
These articleas are written as output of my research on specific topics from the web sites, research papers, news. It contains the output of my analysis with LLMs support.
Innovations in training LLMs
Imagine training a math genius AI that first aces math problems, then masters coding challenges – and does so by learning from trial and error like a human, rather than just imitating textbooks. That, in a nutshell, is AceReason-Nemotron (2025), a new large language model (LLM) from NVIDIA that tackles complex math and programming problems using reinforcement learning (RL). It’s a departure from the usual recipe of just feeding models tons of solved examples. Instead, AceReason-Nemotron learns by generating answers, checking if they’re correct, and tweaking itself based on success or failure. This approach has allowed a 14-billion-parameter model (and even a 7B version) to outperform many models that were previously considered state-of-the-art in math and code reasoning .
The paper from Nvidia introduces AceReason-Nemotron , a family of reasoning models (7B and 14B) that significantly improve math and code reasoning through large-scale reinforcement learning (RL). The authors challenge the belief that RL is only effective for very large models and show that smaller models also benefit.
Contributions
Main Contributions
1. RL works for small/mid models: AceReason-Nemotron-7B/14B trained with RL outperformed state-of-the-art distilled models like DeepSeek-R1-Distill on both math and code benchmarks.
2. Sequential training:
- First, models are trained with math-only RL.
- Then, they are fine-tuned with code-only RL.
- Math-RL alone improves code reasoning (+6.8% / +5.8% on LiveCodeBench).
- Code-RL boosts code skills without hurting math skills.
3. Verified high-quality datasets:
- Math data: filtered from DeepScaler and NuminaMath, with symbolic verification using SymPy.
- Code data: collected from platforms like AtCoder and LeetCode, validated via execution-based test cases.
4. Technical innovations:
- On-policy RL using GRPO (variant of PPO).
- Curriculum learning with increasing token limits (8K → 32K).
- Training on hard prompts for better performance gains.
- Strict binary reward signals to avoid false positives/negatives in code RL.
Insights
- RL improves pass@1 and pass@k scores.
- Math RL improves non-math code topics (e.g., Graphs, Dynamic Programming).
- RL helps models solve previously unsolvable problems.
- Best results achieved by starting with 8K token limit, then expanding.
- Reinforcement learning is not only viable for small/mid-size models but superior to distillation in many reasoning tasks when applied properly. This challenges conventional LLM training paradigms and provides a reproducible recipe for training powerful, general-purpose reasoning models.
Topics
Here is an in-depth explanation of the four key training strategies used in AceReason-Nemotron, with technical and conceptual insights:
1. On-policy RL using GRPO (Generalized Rejection Policy Optimization)
GRPO is a reinforcement learning algorithm inspired by PPO (Proximal Policy Optimization), but adapted for LLM training with a key simplification: no separate value function is required.
Why on-policy?
- In on-policy RL, the agent (model) learns from fresh experiences generated by the current policy.
- This contrasts with off-policy RL, where learning can happen from older data produced by previous versions of the policy.
Implementation in AceReason:
- For each prompt (question), the model generates multiple outputs (rollouts) using the current policy.
- Each rollout is scored with a rule-based reward function (1 = correct, 0 = incorrect).
- The advantage of each token is computed using normalized rewards across the batch.
- A clipped policy gradient update is applied to ensure stable updates without collapsing the model’s output distribution (entropy collapse).
- Only one gradient update per batch of rollouts is used (strictly on-policy) to prevent destabilization and overfitting.
Key Benefits:
- Simpler and more efficient than PPO (no critic).
- Prevents training collapse caused by overfitting on stale or synthetic data.
- Yields stable improvements in reasoning ability, especially in symbolic tasks.
2. Curriculum Learning with Increasing Token Limits (8K → 32K)
Curriculum learning gradually increases the difficulty or complexity of training data—in this case, by increasing the allowed response length (token limit) over stages.
Stages used:
- Start at 8K tokens: encourages concise reasoning.
- Progress through 16K, 24K, to 32K tokens: allows more detailed, complex reasoning.
Motivation:
- Initially short responses reduce training cost and encourage focused generation.
- As the model improves, longer responses are introduced, which enable more complex chains of thought (e.g., proofs or nested code logic).
- Prevents models from being overwhelmed early on.
Observed Effect:
- Performance improves sharply at the 16K stage due to better utilization of reasoning depth.
- Final model performs best when curriculum includes early training at 8K, then gradual expansion.
3. Training on Hard Prompts for Better Performance Gains
Selective training on harder prompts—examples the model initially performs poorly on—is used to push the model’s capabilities.
How difficulty is estimated: A prompt is considered hard if a strong model (e.g., DeepSeek-R1) fails to solve it consistently over multiple attempts (e.g., < 6/16 pass rate).
Curriculum tiers:
- Easy: >14/16 passes
- Medium: 10–14/16
- Hard: ≤6/16
Why hard prompts matter:
- Easy prompts provide little learning signal once solved.
- Hard prompts maximize gradient signal and help models learn strategies they lacked before.
- Encourages generalization to out-of-distribution or rare reasoning patterns.
Evidence from the paper: training with only hard prompts during Stage 3 of math RL improved AIME24 accuracy +2.6% more than training on the full dataset.
4. Strict Binary Reward Signals to Avoid False Positives/Negatives in Code RL
In code generation, RL relies on execution-based rewards: a solution is considered correct if it passes all test cases.
What they did:
- Used strict binary reward:
- Reward = 1 if code passes all test cases.
- Reward = 0 otherwise.
- No partial credit or heuristic scoring.
Why this matters:
- False positives: Occur when flawed code accidentally passes weak test cases. Rewarding these teaches the model incorrect logic.
- False negatives: Occur when correct solutions fail due to buggy test cases. Penalizing these discourages correct strategies.
Avoiding them:
- Carefully curated test suites that:
- Cover edge cases, large inputs, and corner conditions.
- Avoid known flaky or multi-solution problems.
- Excluded test cases from weak models like DeepCoder that failed to catch incorrect but passing outputs.
Impact:
False reward signals can cause:
- Training collapse (model learns to exploit test flaws).
- Performance drop on strong benchmarks (real-world tests).
- By ensuring reliable binary feedback, the model learns robust algorithms rather than gaming the reward system.
What is GRPO?
Here’s a deep dive into GRPO (Generalized Rejection Policy Optimization), especially as applied in the AceReason-Nemotron paper:
GRPO is a reinforcement learning (RL) algorithm that extends and simplifies PPO (Proximal Policy Optimization) to suit the needs of large language model (LLM) training — especially for long-form reasoning tasks like math and code.
It was introduced in the context of DeepSeek-R1 and further refined by AceReason.
Motivation
While PPO is powerful, it requires:
• A separate value function network (critic),
• Careful tuning of KL-divergence penalties,
• And can be unstable with long sequences or when feedback is sparse (like math/code verification).
GRPO avoids these issues by:
• Removing the value function (no critic needed),
• Using rule-based or verifiable rewards (e.g., correct answer = 1, incorrect = 0),
• Performing strict on-policy updates, stabilizing training.
How GRPO Works
Step-by-step overview:
1. Start from a strong supervised model (like DeepSeek-R1-Distill-Qwen-7B/14B).
2. For each prompt (𝑞): Sample 𝑮 outputs {𝑜₁, …, 𝑜𝒢} using the current policy (πₜ₋₁).
3. Assign rewards (𝑆ᵢ) to each output (𝑜ᵢ):
• Math: correct final boxed answer → reward = 1, else 0.
• Code: passes all test cases → reward = 1, else 0.
4. Compute normalized advantage. This reflects how much better a response is compared to others in the batch.
5. Policy update
6. KL term is dropped (β = 0), simplifying the objective.
7. One gradient step is applied per rollout batch, making it truly on-policy.
Key Technical Advantages
- No value function Avoids training instability from critic learning
- On-policy updates Prevents overfitting to stale samples
- Normalized advantage Stabilizes learning signal within batch
- Token-level granularity Fine-grained control in long-sequence learning
- Clipping Prevents large, destabilizing updates (like PPO)
- Simplified reward model Leverages verifiable correctness for math/code
Practical Insights from the Paper
- Entropy collapse is a real issue: Too many updates per batch = model degenerates.
- Strictly one update per batch preserved exploration (i.e., model keeps trying new strategies).
- Drop in KL divergence penalty did not hurt performance — thanks to verifiable, sparse rewards.
- GRPO with curriculum learning (8K → 32K) made RL stable even at high model scale (14B).
GRPO is a domain-specific optimization of PPO designed to make RL work effectively and efficiently for large language models in symbolic domains (math, code). Its design prioritizes:
- Simplicity (no critic),
- Stability (on-policy, clipping),
- Precision (token-level control),
- And efficiency (no KL term, verifier-based rewards).
It’s emerging as a standard for LLM fine-tuning in high-verifiability tasks.

Comments and in-depth analysis
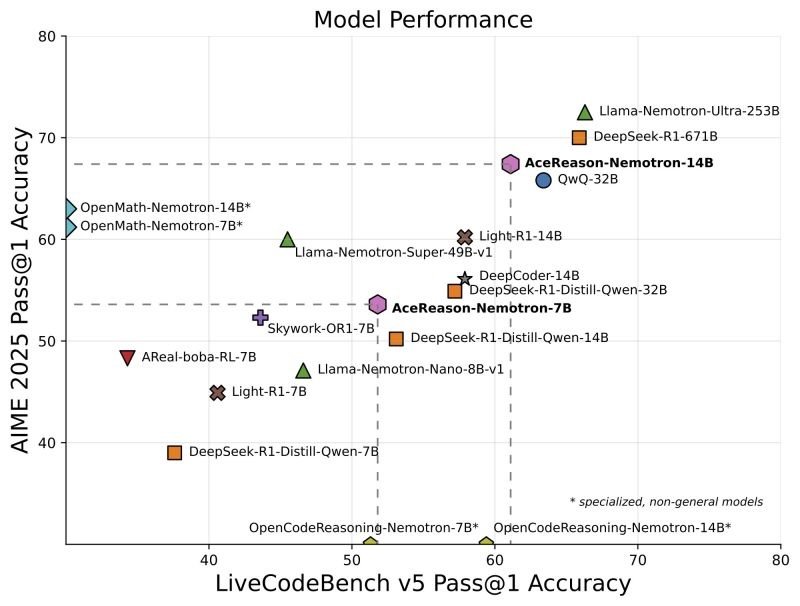
Why does AceReason-Nemotron matter? It shows that reinforcement learning – essentially _learning by getting reward for correct answers – can push a mid-sized AI model’s reasoning ability to new heights, beyond what was achieved by simply distilling knowledge from larger models.** In previous efforts, smaller models often learned reasoning by distillation (basically copying a larger teacher model’s behavior) because pure RL was tricky and sometimes less effective . AceReason-Nemotron flips the script by demonstrating a successful RL training recipe for reasoning tasks, matching or surpassing specialized models that were built with supervised learning. For example, AceReason-14B beat the distilled OpenMath-14B model on math contests by ~4% and outperformed OpenCodeReasoning-14B on coding benchmarks . It even outshines LLaMA-Nemotron (an earlier distilled LLM) by a wide margin . In plain terms, AceReason is closing the gap between efficient mid-sized open models and giants like GPT-4 on niche reasoning tests. While GPT-4 remains a powerful generalist, AceReason’s focused training gives it an edge on specific benchmarks – for instance, it scores ~78.6% on the AIME 2024 math exam and ~61% on a competitive coding test (LiveCodeBench v5), competitive with some 30B+ models and not far from GPT-4 on those tasks .
How is AceReason-Nemotron different from other math/code LLMs? Most models in the math and code domain (like OpenAI’s GPT-4, or open models like OpenMath and OpenCodeReasoning) rely heavily on supervised training: they learn from a fixed dataset of solutions or from distilling a larger model’s knowledge. AceReason, however, is trained via reinforcement learning with a “reward if correct” signal, which is more akin to how a student learns by trying to solve problems and checking the answers. The training was done in two phases: first on math problems, then on code problems . This sequential strategy is key – the math training built a strong reasoning foundation that surprisingly also improved coding performance (the model got better at coding tasks just by first doing math RL!) . After that, focused training on coding further boosted its programming prowess without ruining its math skills . In addition, AceReason-Nemotron’s training involved a few clever tricks that set it apart in the reasoning LLM space:
Curriculum learning: It doesn’t dive into the hardest problems or longest solutions right away. Instead, it gradually increases the complexity and length of responses, starting with an 8K token limit and eventually expanding to 32K tokens as the model improves . Easier prompts and shorter answers first, then longer, harder problems – just like a student progressing from basic to advanced material.
“Hard” prompt filtering: As the model got better, the trainers filtered out problems it could already solve easily, forcing it to focus on unsolved or difficult questions . This ensured continuous learning rather than over-practicing the same easy questions.
Strict verification-based rewards: AceReason only gets a reward when it’s completely correct. For math, that means the final answer matches the ground truth; for code, the program must pass all unit tests. There’s no partial credit. This binary all-or-nothing reward is a bit risky but powerful – it trains the AI to be absolutely correct, not just “pretty good.” A special set of verifier programs checks each answer and signals 1 for success or 0 for failure, ensuring the feedback is grounded in factual correctness.
These differences make AceReason-Nemotron feel less like a parrot of internet text and more like a problem-solving apprentice that’s being rigorously coached. Next, we’ll dive into the technical details of how these innovations work under the hood, for those curious about the RL training recipe that produced this standout model.
Under the Hood: Technical Innovations in AceReason-Nemotron
Now let’s get technical and explore how AceReason-Nemotron’s training process works. The team introduced several innovations to stabilize and optimize reinforcement learning for an LLM:
GRPO – Reinforcement Learning Without a Value Network
AceReason-Nemotron uses an algorithm called Generalized Rejection Policy Optimization (GRPO) as its RL backbone . GRPO is a variant of policy optimization tailored for language models, and it’s simpler than the popular PPO (Proximal Policy Optimization) because it doesn’t require a separate value function network . In GRPO, the language model itself is the “policy” that generates answers, and we evaluate those answers with a reward function.
Here’s how a training step works in pseudocode, illustrating the GRPO idea:
for prompt in training_prompts:
# 1. The model generates a group of possible answers (rollouts) for the prompt
rollouts = [model.generate(prompt) for _ in range(group_size)]
# 2. Each answer is checked by a verifier, giving a reward 1 (correct) or 0 (wrong)
rewards = [verify_answer(prompt, answer) for answer in rollouts] # reward ∈ {0,1}
# 3. Compute relative advantages by subtracting the average reward (baseline)
baseline = sum(rewards) / len(rewards)
advantages = [r - baseline for r in rewards] # centered rewards
# 4. Update model weights to increase log-probability of answers with positive advantage
model.update_policy(rollouts, advantages) # gradient ascent stepInstead of using an explicit value model to predict expected reward, GRPO uses the group’s average reward as a baseline. Essentially, the model compares its answers against its own mini “sample” of other answers. Correct answers in the group get a positive advantage (since their reward 1 is above the baseline average) and wrong answers get a negative advantage. The model then nudges itself to be more like the correct attempts and less like the incorrect ones. This relative, group-based advantage formulation makes training stable and avoids some of the complications of PPO (no need to tune a value head or worry about value loss terms). Notably, AceReason’s training was kept strictly on-policy, meaning the model was updated immediately after generating the batch of rollouts and only one gradient update per batch . This conservative update rule (no multiple epochs over the same data) helped prevent collapse of the model’s output diversity – an issue the authors encountered when they tried more aggressive updates. By sticking to one update per new rollouts (and even disabling the usual KL-divergence penalty term used in some RLHF setups ), they maintained the policy’s entropy (exploration) and avoided the model devolving into repetitive answers.
Curriculum Learning: Longer Solutions and Harder Problems
Training an LLM with RL on reasoning tasks can be unstable, especially if you allow very long, complex answers from the start. AceReason-Nemotron’s team employed curriculum learning in two clever ways: increasing answer length gradually and ramping up problem difficulty.
Expanding response length: The model started RL training with a maximum answer length of 8K tokens, even though the architecture could handle more. Once it learned to solve problems within that limit, the limit was raised to 16K, then 24K, and finally 32K in later stages . This staged expansion let the model “grow” its chain-of-thought after solidifying its skills at shorter lengths. Interestingly, when they tried to start directly at, say, 24K tokens, the model struggled at first . But starting at 8K and incrementally increasing led to faster learning and higher final accuracy . Essentially, the model first learned to be concise and coherent within a shorter limit, and then capitalized on extra length to reason more deeply once it was ready. During the 8K stage there was a brief drop in performance (since the model had to compress its reasoning initially), but as soon as the limit increased to 16K, the model eagerly filled the extra space with more detailed reasoning, and its accuracy jumped significantly . This suggests that letting the model think longer (more tokens) directly translated to solving more problems, once it had the foundation in place.
Focusing on hard prompts: As AceReason improved, the trainers filtered the dataset to emphasize unsolved and challenging problems. In the third stage of math RL (around the 24K token stage), they created three subsets of problems – Easy, Medium, and Hard – defined by how often a preliminary model could solve them in many tries . “Easy” prompts were those the model solved most of the time; “Hard” were those it seldom solved. The authors then fine-tuned the curriculum by actually dropping the easiest problems and training only on the hardest ones, which yielded the best gains . Table 3 of the paper shows that using the Hard-only set beat the full set by about 2.6% on the AIME math benchmark . In other words, once the model had learned all it could from easier questions, focusing its efforts on head-scratchers pushed its reasoning ability further. This is intuitive – it’s like a student who, after mastering basic exercises, moves on to only past exam challenges for practice. By the end of training, AceReason-Nemotron was largely learning from its mistakes on the hardest problems, because all the low-hanging fruit was filtered out. This curriculum strategy ensured continuous improvement and prevented wasted time on trivially solvable prompts.
Binary Rewards and Verifier Checks – Strict Feedback for Code
One of the most distinctive aspects of AceReason-Nemotron’s RL training is the use of strict binary rewards guided by automated verifiers. The reward function isn’t a fuzzy score; it’s essentially 0 or 1, indicating “solution wrong” or “solution correct.” For math problems, the verifier checks if the model’s final answer matches the known correct answer exactly. For code problems, the verifier runs the model’s code against a suite of test cases. If the code outputs the expected results for all tests, the reward is 1; if it fails any test, reward 0. Here’s a simplified example of what these verifiers might look like:
def verify_math(solution, correct_answer):
return 1 if solution.strip() == correct_answer.strip() else 0
def verify_code(code_solution, test_cases):
for test in test_cases:
output = run_code(code_solution, test.input)
if output != test.expected_output:
return 0 # fails this test, no reward
return 1 # passes all tests, reward = 1This all-or-nothing scoring may sound harsh, but it aligns perfectly with the nature of math and programming tasks – an answer is either correct or not. It also prevents the model from being “satisfied” with partially correct reasoning. However, such binary rewards require extremely reliable checking mechanisms. The AceReason team put significant effort into curating high-quality verification data:
For math, they pooled problems from challenging math datasets (like DeepScaler and NuminaMath) and **used an existing strong model (DeepSeek-**R1) to generate candidate solutions, then verified those solutions with rules to build a clean set of question-answer pairs . This provided a trusted training set of math questions with definitive answers for the RL to use as ground truth.
For code, they scraped thousands of coding problems from competitive programming platforms and constructed comprehensive test cases for each, including tricky edge cases . They even assigned difficulty scores using a massive 671B model to ensure a range of easy to very hard problems. By having strong test suites, they minimized the chance of “false positives” – cases where buggy code accidentally passes weak tests and gets a reward. The paper actually discusses how flawed reward signals (false positives or false negatives) can derail RL training . If the model ever gets a reward for a wrong solution (a false positive) or gets no reward for a correct solution due to a bad test (false negative), it can learn the wrong lesson. Such mistakes can cause the policy to collapse or converge to suboptimal behaviors . AceReason’s strict verification pipeline was designed to eliminate these reward errors, ensuring the model only gets positive reinforcement for truly correct reasoning. This strictness is one reason the model achieved very high accuracy – it wasn’t allowed to think an answer was “good enough” unless it was entirely correct.
Two-Stage Training: Math First, Code Next
A core idea of AceReason-Nemotron is training in two stages: Stage 1 with math-only RL, then Stage 2 with code-only RL
The reasoning behind this is fascinating. Math problems require logical thinking, planning, and step-by-step reasoning (often called chain-of-thought), which builds a sort of “core” reasoning skill in the model.
By fine-tuning on math first, the model learned to reason through complex tasks in a stepwise manner (and indeed, AceReason’s responses for math are long step-by-step proofs or derivations up to the token limit).
This math training not only boosted its math test scores by huge margins (+14–17% on a challenging contest benchmark AIME 2025 compared to the baseline) but also gave a surprise bonus: the model’s coding ability improved too!
After the math-only RL phase, AceReason-7B and 14B both saw their scores on a coding benchmark (LiveCodeBench) jump by 5–7% , despite not having seen any code yet in RL.
The paper attributes this to cross-domain generalization – essentially, the model’s improved logical reasoning carried over to writing and debugging code .
Armed with this enhanced general reasoning skill, the model then underwent code-specific RL training.
In the code RL stage, it practiced generating correct programs and got feedback from the test-case verifiers.
Starting the coding phase with a math-RL-pretrained model gave a much better starting point than starting from the original model, leading to higher final coding accuracy.
Crucially, doing additional code RL did not erase the math ability – the final model still performs almost as well on math as it did after the math stage, showing that the two skills can coexist.
The end result is a balanced reasoning model that excels at both domains, aptly named AceReason for its prowess with tricky problems.
How Does AceReason Stack Up Against Other Models?
AceReason-Nemotron-14B’s results are turning heads in the AI community because this relatively compact model is competing with or outperforming models two to four times its size on math and coding challenges.
To put its performance in perspective:
Versus GPT-4: GPT-4 is a much larger, closed-source model known for excellent reasoning. AceReason-14B doesn’t match GPT-4 on everything, but on specialized benchmarks like AIME (math competition problems) and LiveCodeBench (coding challenges), AceReason is remarkably strong for its size. It has essentially narrowed the gap, achieving scores that were once only reachable by the very largest models. This suggests that targeted RL training can make a mid-size model punch above its weight. (For instance, an earlier 340B “Nemotron” model reportedly matched GPT-4 on some tasks – AceReason shows even a 14B model can reach that league in narrower domains.)
Versus DeepSeek-R1: DeepSeek-R1 (2025) was one of the pioneering open RL-trained reasoning models . However, the original DeepSeek-R1 was a very large model (hundreds of billions of parameters) and its recipe wasn’t fully disclosed. AceReason leveraged DeepSeek-R1’s distilled offspring as a starting point (the 14B Qwen-based distilled model) and managed to surpass the teacher. After RL, AceReason-14B significantly outperforms the DeepSeek-R1 distilled 14B model on both math and code benchmarks . This is a big deal: it means the student (via RL fine-tuning) not only learned the teacher’s knowledge but discovered new ways to solve problems even better. It validates that RL can unlock capabilities beyond supervised distillation.
Versus OpenMath and OpenCodeReasoning: These models (OpenMath-14B, 32B, etc.) were state-of-the-art specialist models trained via distillation on math or code tasks . AceReason-14B outperforms OpenMath-14B on math by a couple of percentage points and even edges out the 32B version on some math tests . On coding, AceReason-14B is slightly ahead of OpenCodeReasoning-14B as well . At the 7B scale, the picture is interesting: AceReason-7B does about as well as OpenCodeReasoning-7B on code, but OpenMath-7B still has a lead on math . This implies that for very small models, distillation from a huge teacher might still be a strong method (OpenMath-7B likely distilled knowledge from a giant model, giving it an edge in math). But by 14B, AceReason’s RL approach clearly beats distillation, reaching a higher ceiling of performance .
Versus LLaMA-Nemotron: LLaMA-Nemotron (2025) was another effort where a LLaMA-based model was trained for reasoning via distillation (Nemotron). The AceReason paper reports that AceReason models “significantly outperform” LLaMA-Nemotron models of similar size . This reinforces the idea that how you fine-tune a model matters greatly: RL, when done right, can extract more from the model than imitation learning alone, at least on these complex reasoning tasks.
Sources: Yang Chen et al., AceReason-Nemotron: Advancing Math and Code Reasoning through Reinforcement Learning (NVIDIA, 2025) , and associated project releases.